




Background
Getting a project to work is great. Getting it to work the best possible way is better. I wanted to build a simple system the "right" way. What is the "right" way? We have seen books and articles about how things should be built for production use. Caching, redundancy, rate-limiting and proxy are popular items in this context. I'll be going all out to create a very simple application using these concepts.
It's time to choose a project. I built several websites that dealt with audio one way or the other. I usually need a way to get the length of the media file from its URL. Why not build a service that does that? The requirements were very simple. It is a system that takes the URL of a media file as input and returns the metadata of the file.
I promise to keep this article free of code. It is a description of the architecture and what it stands to achieve. Let's get started.

Wrapping FFmpeg with server
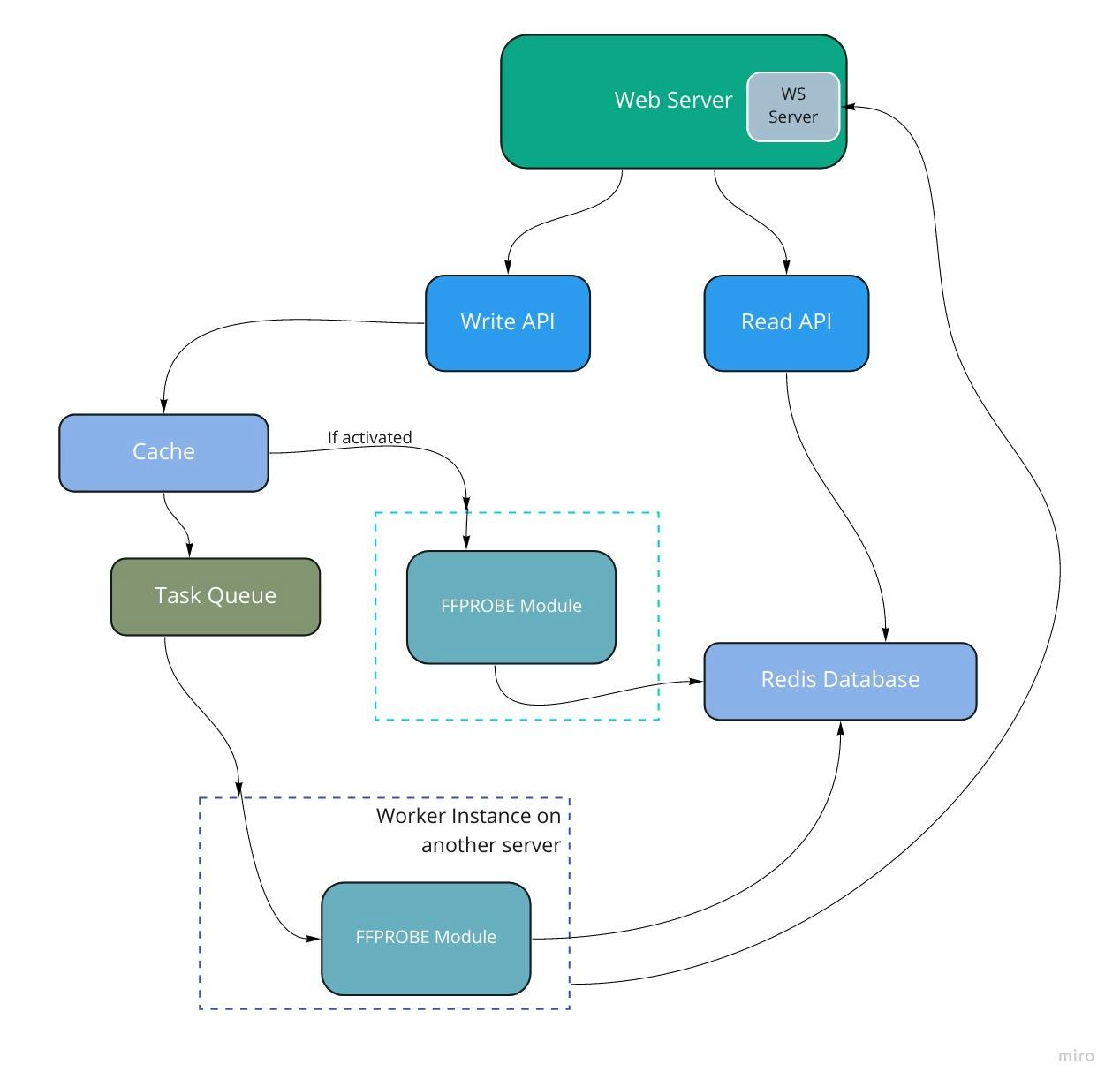
FFmpeg is the workhorse of this application. FFmpeg is open-source software for all kinds of media manipulation. FFmpeg comes bundled with another program called FFprobe. FFprobe does one thing, and it does it very well. It can get the metadata of a media file from the file itself as well as its URL. This is exactly what I needed. To keep things simple, I used an FFprobe wrapper written in Golang for this purpose. This small unit called the FFprobe module in the image below.
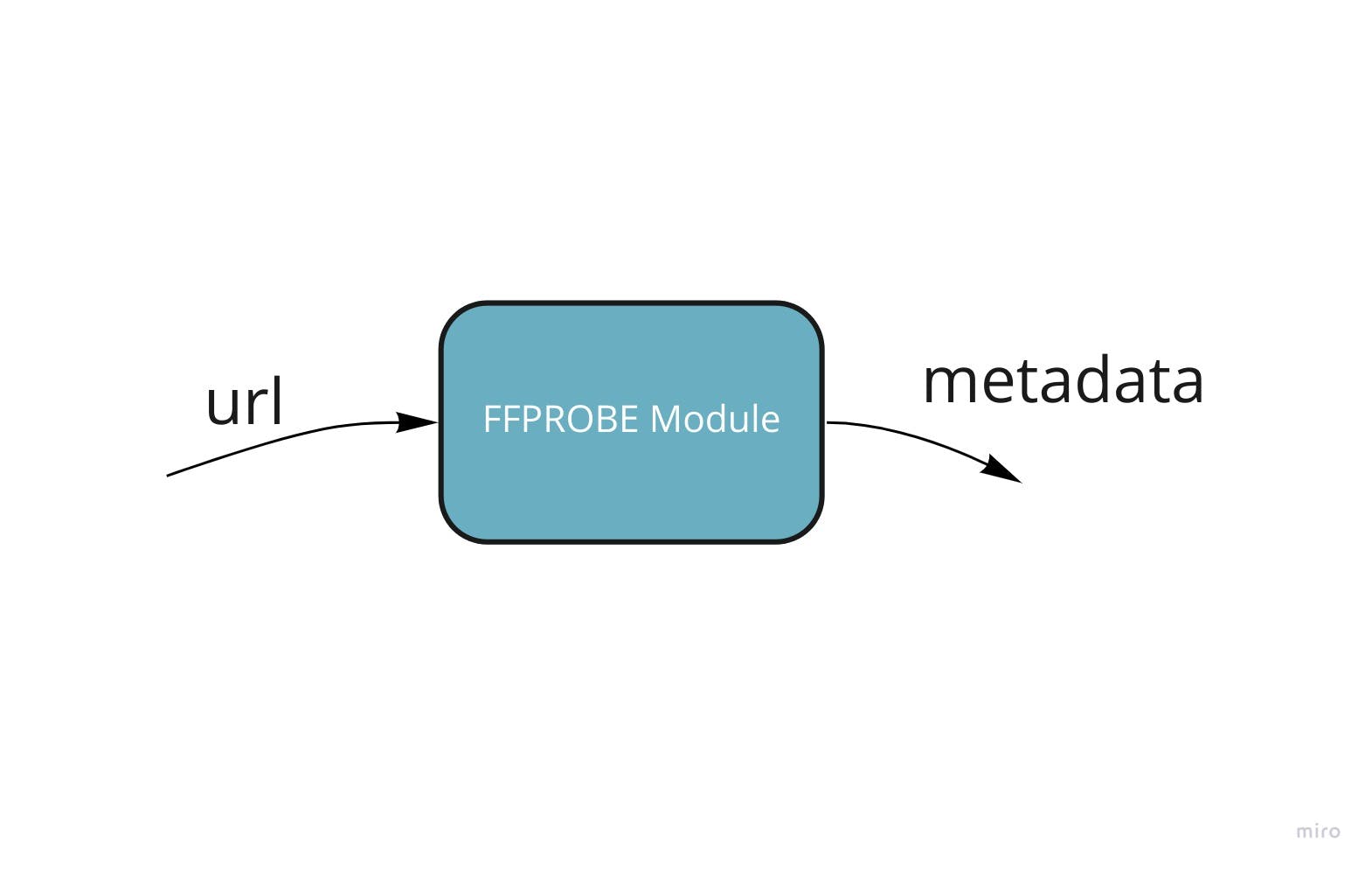
Making a web server to wrap this module up was easy. I used the Iris Framework and created an endpoint. This endpoint takes the URL of the file, runs it through the module, and returns the result (the metadata of the file). Simple but slow. Moving on.
Since a client can't give a payload and get a response at the same time, we need to have two endpoints. One for initiating the processing of a URL and another for fetching the result. We would need a way to persist data for the user after processing it. We need a storage of some sort and a way to recognize our request. A UUID can be assigned to recognize the request the store the result of the process for a fixed amount of time. We get to use a lower amount of storage. This is a great use case for Redis. We can map the UUID to the result of the processing. At this point, the system looks like the one below.
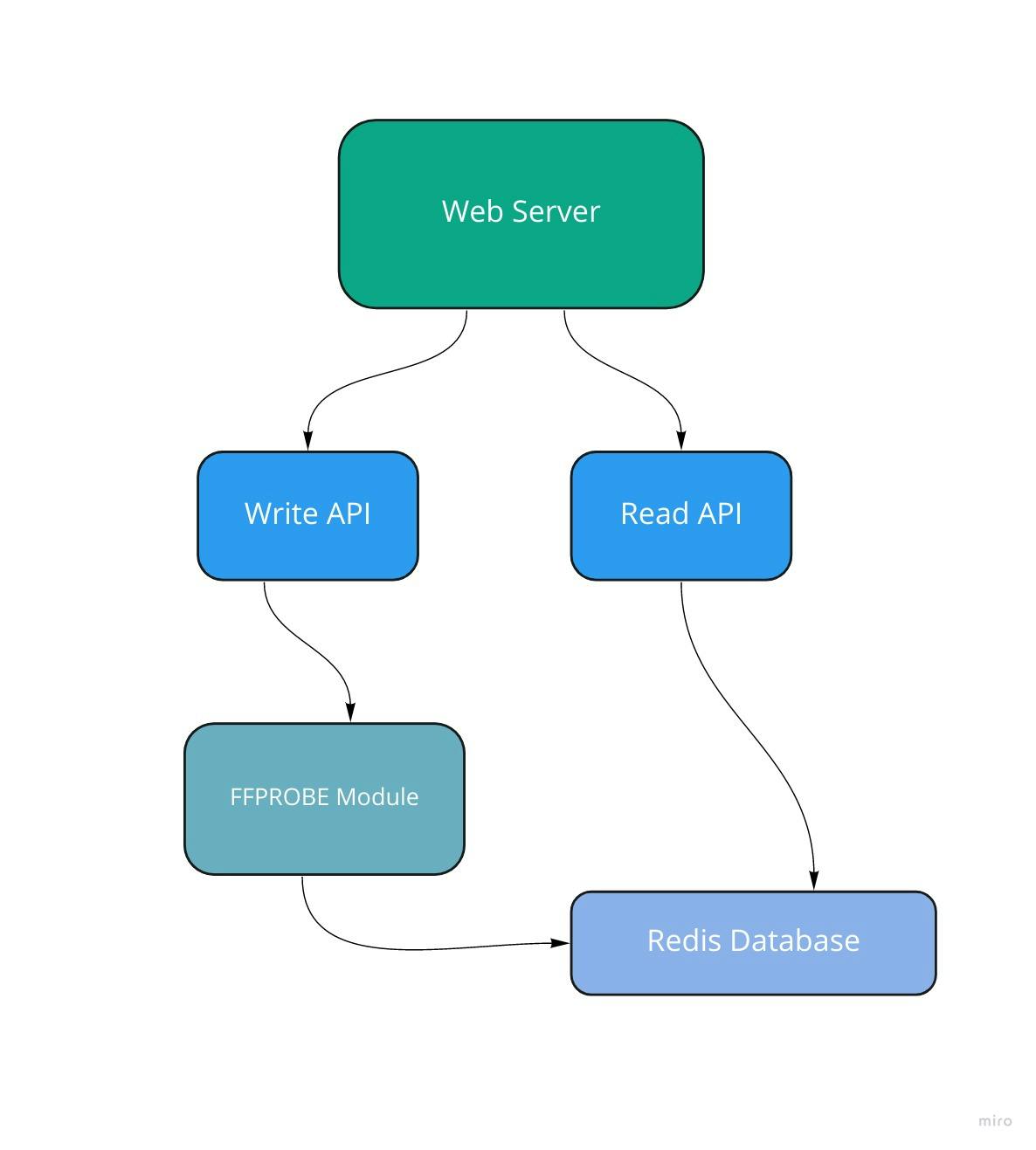
The expiration time of the stored data is set to 3 hours. Redis will remove stale data and free storage space automatically. Now, we have a complete and deployable solution. Can we improve it? Yes.
Caching for speed
We do not have to process a URL every time. We should store the results of already processed URLs. The probability of the media at the end of a URL changing within 3 hours is very low. Low enough to be worth the risk in exchange for better performance. Again, Redis is the perfect tool for this. We map a URL to a UUID, which then maps to the result. We return status code 200 if the result already exists or return 202 if we have to process the request. After processing, the result is stored in Redis to serve as a cached result for another request. We can also set the expiration time of the cached data to be 3 hours, and Redis will automatically remove stale data and free storage space.
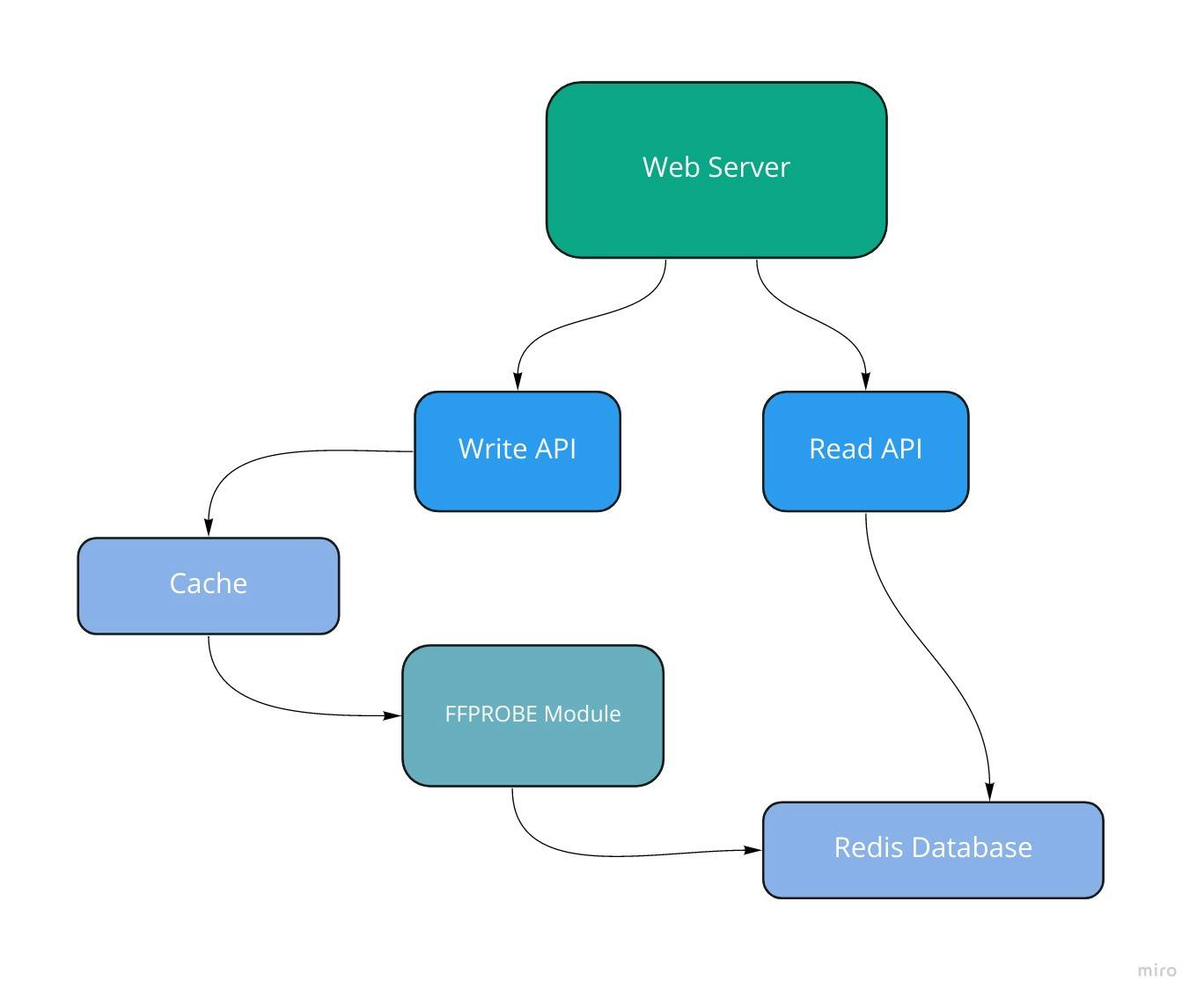
Before moving on, there's another question to answer. Should we cache errors? My answer is no. If the URL points to an unavailable media file, it will fail. This unavailability can be due to downtime or network issues. It's not a good idea to cache an error. Every reattempt should be to get a successful response, which is then cached. The layered middleware architecture of Iris allows me to do this very easily.
Adding worker instances
At this point, the API server processes the URL. This isn't the best as a server won't be able to step up to handle requests. We can offload the processing to another server instance. This server's only job is to run the FFprobe module and process our requests and jobs. Such a server instance is a "worker instance," and all it does is work. Many worker instances can co-exist. They can work together leading to improved speed and availability. The API server "communicates" with the workers via a task queue. Task queues let applications perform work (tasks), asynchronously, outside of a user request. If an app needs to execute work in the background, it adds tasks to task queues. The tasks are executed later, by worker services.
While there are lots of choices for task queues, I settled for RabbitMQ. The API server publishes to the task queue, and the worker instance fetches the task and executes it. The system looks as shown below.
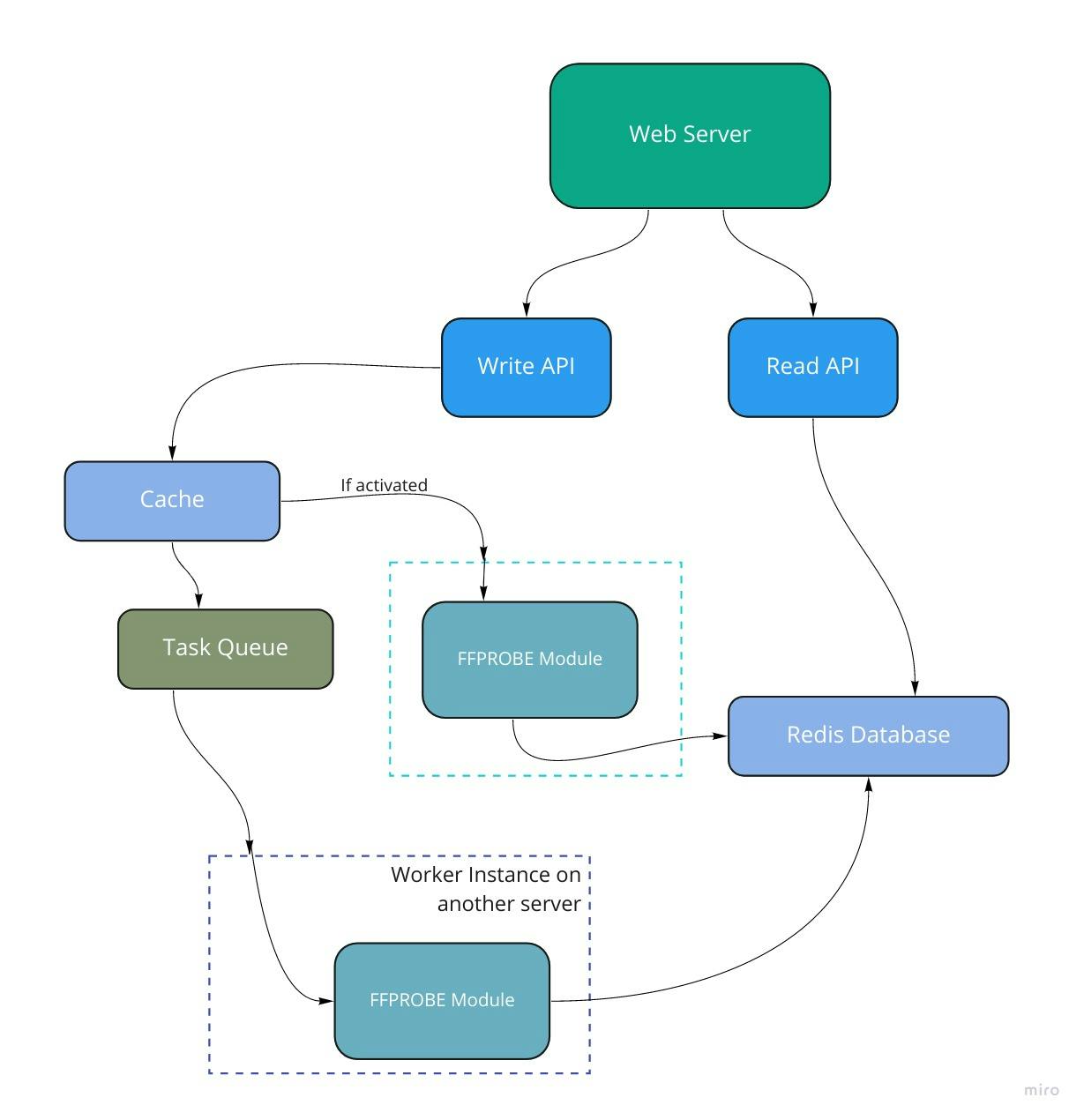
I added a "lil-something" to this architecture. This is the ability to choose where the processing should be done. That is, I didn't get rid of the FFprobe module in the API server but will switch between them based on a flag. That way, I was able to host the application on Heroku without wasting lots of my free hours running a worker instance. Cheap? Maybe 🤣.
Real-time feedback
The existing architecture meant that the clients had to poll the server for results. It means more load for the server, and client applications won't run optimally. This is why a form of real-time communication is required to keep the client aware at all times. SocketIO to the rescue! It is a simple integration and it goes as such.
The client connects to the API server before sending in a request. The server issues an ID for the client. This ID is sent along with the URL in the payload. The server queues the request and returns the status code 202. The worker instance also connects to the API server and emits an event when it is done. This event contains the SocketIO ID of the user and is propagated to the user. If the processing is done on the API server, the server simply emits a "completed" event to the client. To cap it all, it's not a necessity to listen for events, the system will work regardless. By now, the system looks as shown below.
Closing Remark
The goal of the project was to build a simple project the "right" way. It was fun and it ended with me learning a lot in the process. The project can be found on GitHub at github.com/teezzan/worker.
After concluding the project, I reached out to two of my developer friends. I asked if they were willing to use the project for a small project. They agreed and the result was awesome. You can check them out at Metaworka (built by Temitayo Ogunsusi ) and Durator(built by Abdullah Abdul-Fatah). Temitayo went a notch higher by allowing you to upload your files to file.io, generate a URL which is then sent to the backend. Overall, it was an exciting project. Thanks for reading.
