


Table of contents
As software developers, we build systems that take in user inputs and give results. While we can define the state of our system, the input from the user's side can be infinite in possibility. We try to keep it under control by giving a set of rules and validating the input against those rules. It isn't strange to see these validations going on deep inside the codebase. This article is about how you should parse your input and not pass it on to underlying modules.
Why Parse?
We always want to be able to perform our business logic with a level of certainty. Most functions usually start with validation for this reason. Performing input validation for every modular piece of code isn't viable. The resulting code is usually poor and repetitive. This makes the business logic buried within a lot of validation inclined code. This shouldn't be. The ease to define the context and state of your code should make them easy to write. You will agree with me that checking if the age of a user is negative is not a great thing to do deep inside your code. What's the answer? Parse your input and allow it to fail fast.
Our code is usually broken down into modules that pass data from one to another. The first module that user input should encounter should be your parser. At this point, you can convert the input into a predefined data structure and validate it. These data structures should be useable by your underlying modules without worry. Any form of error is thrown as soon as possible and propagated. Such error could be the negativity of age or having a decimal number of kids.
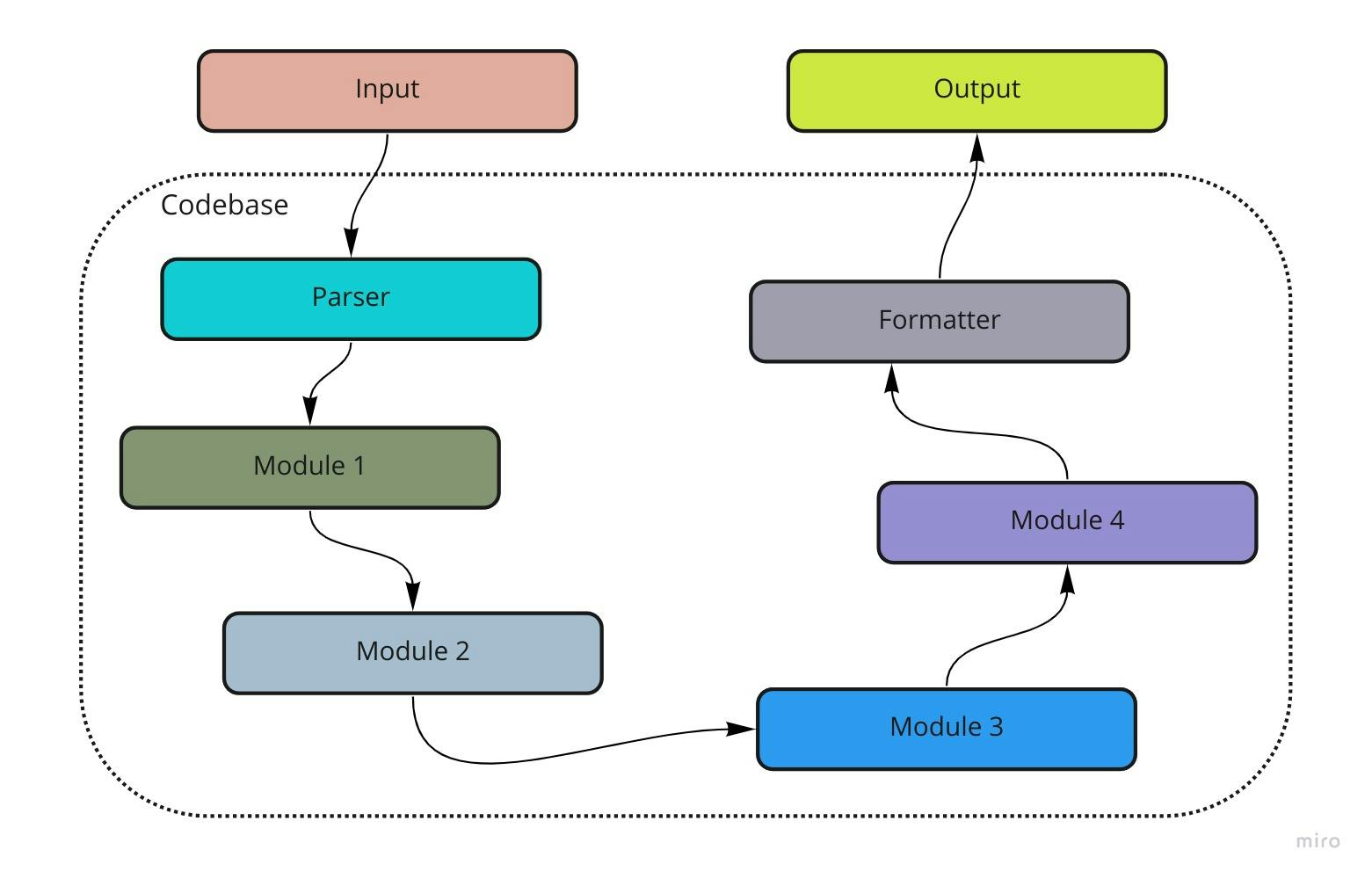
The image below shows a diagrammatic representation of the technique. The rounded squares represent the various modules that make up the application. Notice that some form of parsing and formatting is done at the boundary of user input into the system and output from the system.
How to Parse? This technique is language-agnostic and can differ in implementation in various languages. Generally, strongly-typed languages have it easier than others. Here is an example gotten from a great article titled "Parse, don’t validate, incoming data in TypeScript". It uses the library called Runtypes. A typical implementation goes as follows.
import * as RT from "runtypes"
/*
TS does not support accessing types during runtime, so instead,
we let Runtypes create the type for us using their own Domain
Specific Language (DSL) to declare the schema & type at the
same time.
*/
const UserType = RT.Record({
name: RT.String,
age: RT.Number.withBrand("PositiveInteger").withConstraint((n) => n > 0),
email: RT.String.withBrand("Email").withConstraint(isEmail).optional(),
website: RT.String.withBrand("URL").withConstraint(isURL).optional(),
createdOn: RT.InstanceOf(Date).optional(),
})
// if you want to get the TS type, eg. for function signatures
type UserType = RT.Static<typeof UserType>
declare const data: any // (just so this example compiles)
try {
// "If the object doesn't conform to the type specification, check will throw an exception."
const userType: UserType = UserType.check(data)
console.log(`The User ${userType.name} has arrived!`)
} catch (error) {
console.error(`Oof, data wasn't what we want! ${error}`)
}
From the above example, one can notice several things. Parsing of the user input is done instead of just validation. This parser function either returns a user type or fails in a controlled manner. The business logic is simplified and we need one line of checks for validation of input. Remember that goal of parsing is to process incoming data to a specific data structure or type. Should parsing fail, it should be in a controlled manner. We are assured all incoming data is handled at the very edges of your programs.
What do you gain?
What do you gain from doing this? You stand to have a better and cleaner codebase. This is because your modules or functions will do what they claim to do. They won't be half validation and half business logic. You will be sure that any errors that occur inside of your codebase are not due to external or input problems. Elimination of user input as a source of bug reduces the surface area of a bug and makes debugging easier.
In a nutshell, don’t validate and pass incoming data deep into your code, parse it right away and fail fast if needed.